
LLMOとは、企業やサービス(ブランド)が、生成AIからの推薦確率を最大化するために、情報の出し方や見せ方を構造的に整えていく取り組みです。
その構造設計の土台をつくるためには、LLMの認識構造を理解しておくことが必須です。
LLMは「推薦」を行う前に、まずブランドを意味と結びつけ、一つの存在として内部に整理します。
このプロセスが「認識」であり、認識構造が最適化されていなければ、推薦確率は低くなります。
本記事では、LLMの認識構造がどのように形成されるのかを、わかりやすく解説します。
認識構造は3つの層で成り立っている
LLMでのブランドの認識構造は、以下の三つの層で成り立っています。
① エンティティ
② カテゴリ
③ セマンティッククラスター
この三層により、LLMはブランドを意味的な存在として認識します。
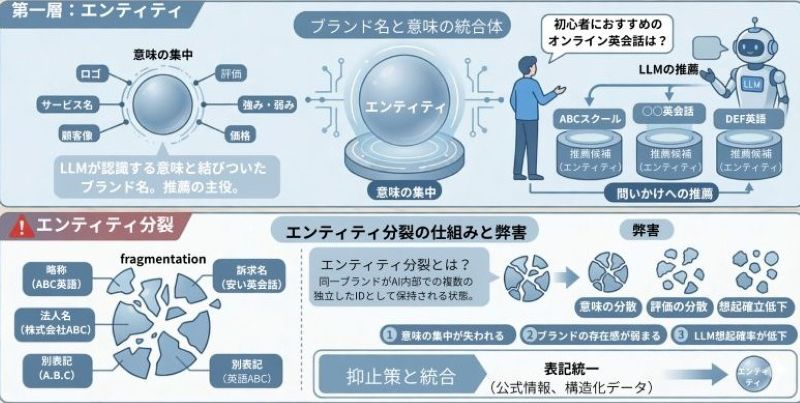
第一層:エンティティ
まず、認識構造の中で主役となるのはエンティティです。
エンティティとは「LLMが認識するブランド名」であり「意味と結びついた存在」です。
たとえば、「初心者におすすめのオンライン英会話は?」
という問いに対して、LLMが「ABCスクール」「〇〇英会話」のように推薦として挙げる意味と一体化した名前が、エンティティです。
このエンティティがLLMの中で安定していないと、ブランドは一つの存在として正しく認識されず、意味や評価が分散してしまいます。エンティティが不安定となる原因としては、エンティティ分裂があります。
エンティティ分裂とは?
本来一つであるはずのブランドが、AI内部で複数のIDとして保持されてしまう状態を、エンティティ分裂と呼びます。
略称・法人名・別表記・訴求名などが統合されていないと、意味や評価が分散し、存在感が弱まります。
エンティティ分裂が起きると、意味の集中が失われ、LLMからの想起確率が下がってしまいます。
エンティティ分裂とその抑止策については、以下の記事で詳細に解説しています。

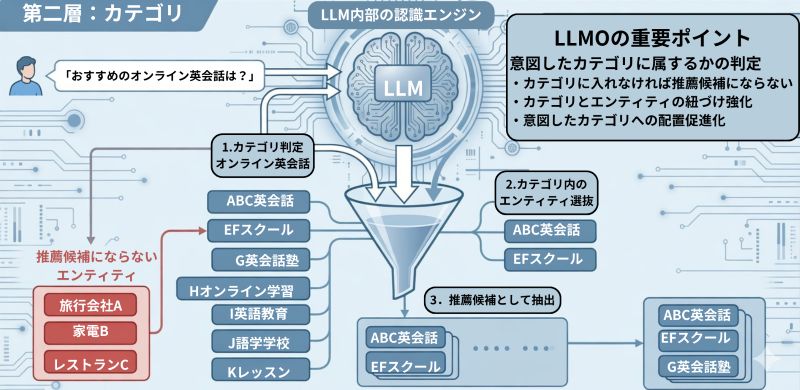
第二層:カテゴリ
LLMは、エンティティを必ず何らかのカテゴリに配置して理解します。
ユーザーが問いを発すると、LLMはまず「これはどのカテゴリの話か」を判定しますが、そのカテゴリに属していると認識されたエンティティだけが、推薦候補となります。
言い換えると、カテゴリに入れなければ、そもそも推薦候補になりません。
そのため、LLMOではエンティティが意図したカテゴリに入っているかも重要なポイントになります。
カテゴリの詳細と最適化については、以下に記事で詳細に解説しています。

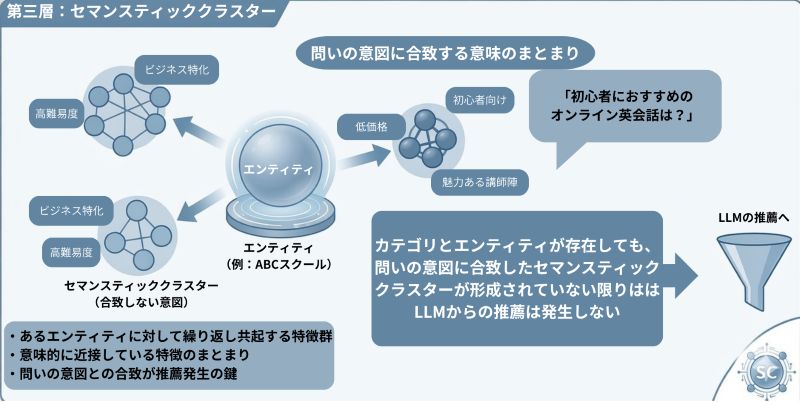
第三層:セマンティッククラスター
セマンティッククラスターとは、あるエンティティに対して繰り返し共起し、意味的に近接している特徴群のまとまりです。
たとえば「初心者におすすめのオンライン英会話は?」という問いに対しては、カテゴリは「オンライン英会話」となり、そのカテゴリの中に「ABCスクール」というエンティティがあるとすると、そのエンティティに紐づいた「初心者向け」「低価格」「魅力ある講師陣」といった意味の集合がセマンティッククラスターとなります。
カテゴリにエンティティが存在したとしても、問いの意図に合致したセマンティッククラスターが形成されていない限りは、LLMからの推薦は発生しません。
セマンティッククラスターの最適な設計については、以下に記事で詳細に解説しています。

三層が整うと何が起きるか
第一層:エンティティが統合され
第二層:カテゴリが固定され
第三層:意味が集中すると
ブランド語は、内部の埋め込み空間で強く固定されます。
これが埋め込み強度の上昇です。埋め込み強度とは、名称と意味がどれだけ強く結合しているかという結果指標です。
埋め込み強度が弱い状態では、LLMから名前は認識されているものの、評価軸との結びつきが浅く、問いによっては推薦候補としてブランド名が出てきません。
一方で強い状態とは、LLMの中で特定の意味とブランド名が強く結びついていて、他候補よりも推薦がされやすくなります。
埋め込み強度とは、推薦されやすさの構造的な土台なのです。
まとめ
認識構造は、LLMOを始める上での基盤となる考え方です。
この認識構造を最適化しない限り、LLMからの安定した「推薦」は起こりません。
本記事を参考に、まずは自社ブランドがAI内部でどのように整理されているのかを見直して、構造設計の第一歩を踏み出してみてください。
また以下の記事では、認識構造を最適化するための項目をチェックリストとして整理していますので、こちらもご参照ください。

※ なお、「エンティティ」「カテゴリ」「セマンティッククラスター」の三層構造は、あくまでもLLMの認識構造を理解しやすくするために論理的に分解した概念モデルです。実際の技術レベルでは、これらはさらに細分化された複数の処理プロセスによって同時並行的に形成されており、明確に三段階に分かれているわけではありません。
- ✔︎自社・競合をスコアリング
- ✔︎効果の高い引用元がわかる
- ✔︎LLMO虎の巻と連動した施策チェックリスト