
生成AIからの推薦は、あらかじめLLM内部で順位が決まっているわけではなく「確率」によって決まります。
では、その確率はどのように形成されるのでしょうか。
LLMOにおいて、推薦の確率を決める鍵は「距離」と「密度」という二つの概念にあります。
推薦とは、比較空間の中で「プロンプトに最も適合し、かつ意味が安定している存在」が選ばれる現象です。その選ばれやすさを構造的に説明するのが、距離 × 密度の座標モデルです。
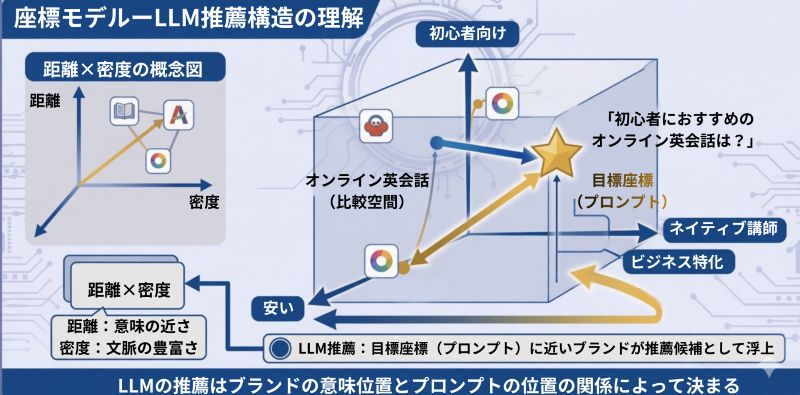
座標モデル ― LLMの推薦構造を理解する
推薦の確率を理解するためには、まずLLMの内部でブランドがどのように整理されているかを理解する必要があります。
LLMの推薦は、意味空間の中に存在するブランドを「座標」として整理し、その位置関係によって選択されます。
この構造を説明するのが、座標モデルです。
座標モデルでは、推薦に関わる要素は次のように整理できます。
・カテゴリ = 比較空間
・セマンティッククラスター = 空間内の意味軸
・ブランド(エンティティ) = 空間内の点(座標)
・問い(プロンプト) = 目標座標
ユーザーからプロンプトが与えられると、LLMはまず「どの比較空間で評価するか」を決定します。
例えば
「初心者におすすめのオンライン英会話は?」というプロンプトであれば、
比較空間は「オンライン英会話」です。
その空間の中では、
・初心者向け
・価格が安い
・ネイティブ講師
・ビジネス特化
といったセマンティッククラスターが意味軸として存在します。
ブランドは、その意味軸の中で「点」として配置されます。
そしてプロンプトは、その空間の中に「目標座標」を置きます。
推薦とは、この目標座標に近い位置にあるブランドが候補として浮上する現象です。
(オンライン英会話:比較空間)
↑ 初心者向け
|
| A社
|
安い ←--------- + ----------→ 高価格
|
| B社
|
↓ ビジネス特化
★ プロンプト
「初心者におすすめのオンライン英会話は?」
→ 目標座標は「初心者方向」に置かれる
→ その座標に近いブランドが推薦候補になる
このように、LLMの推薦はブランドの意味位置とプロンプトの位置の関係によって決まります。
この位置関係を説明する枠組みが、距離 × 密度の座標モデルです。

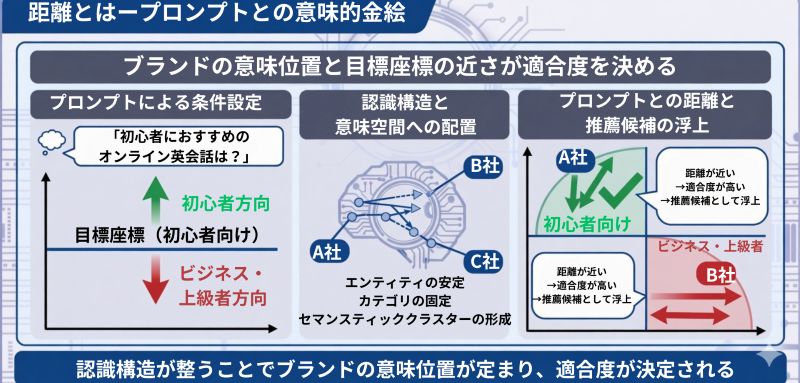
距離とは ― プロンプトとの意味的近接
距離とは、「プロンプトが求める意味」と「ブランドが持つ意味位置」との近さを指します。
ユーザーのプロンプトは、比較空間の中に特定の条件を設定します。
例えば「初心者におすすめのオンライン英会話は?」
というプロンプトでは、「初心者向け」という意味方向が選択の基準になります。
このとき、初心者向けというセマンティッククラスターが形成されているブランドは、比較空間の中で初心者方向に位置します。
その結果、このブランドはプロンプトが置く目標座標に近い存在になります。
一方で
・ビジネス特化
・上級者向け
・法人研修向け
といった意味方向に強く位置しているブランドは、初心者方向から離れた位置に配置されます。
このように、ブランドの意味位置とプロンプトの位置の近さが、推薦候補として浮上するかどうかを左右します。
プロンプト
「初心者におすすめのオンライン英会話」比較空間
初心者向けブランド ● A社
│
│ 距離が近い
───────────目標座標───────────
│
│
│
↓
ビジネス特化ブランド ● B社
A社 → 距離が近い → 適合度が高い
B社 → 距離が遠い → 適合度が低い
この距離は、主に認識構造によって決まります。
・エンティティが安定しているか
・カテゴリが固定されているか
・セマンティッククラスターが形成されているか
このようなLLMからの認識によって、ブランドが意味空間のどの位置に配置されるかが決まります。
認識構造が整っていなければ、ブランドは意味空間の中で適切な位置に配置されず、プロンプトとの距離を縮めることができません。

密度とは ― 意味の集中と一貫性
距離が近いだけでは、推薦は発生しません。もう一つ重要なのが「密度」です。
密度とは、ある意味方向に対して、どれだけ一貫して意味が集中しているかを指します。
この密度は、主に文脈構造で決まります。
ブランドが
・どのような文脈で繰り返し語られているか
・どのような第三者言及が存在しているか
・どのような比較文脈の中で登場しているか
これによって、その意味方向への意味の蓄積量が決まり、その蓄積の強さが、意味空間の中での密度を形成します。
たとえば、同じ「初心者向け」という位置にあるブランドでも、一部の記事だけで語られている、第三者文脈がほとんど存在しない、比較記事の中で安定して登場していないなどの場合、その意味方向への共起は弱く、密度は低い状態になります。
一方で、公式サイト、ブログ記事、プレスリリース、比較記事すべてで一貫して「初心者向けオンライン英会話」という文脈で語られている場合、その意味方向に意味が蓄積されていきます。
このように複数の情報源で同じ意味軸が繰り返し現れることで、意味空間の中ではその方向の密度が高まります。
そして密度を形成する主な要素は、以下です。
・意味の反復と連動
・第三者文脈
・比較文脈
・ストーリーの一貫性
これらが揃うことで、意味は時間方向に蓄積され、安定した文脈として固定されます。

推薦は「距離× 密度」で決まる
推薦確率は、単純な足し算ではありません。
距離が近くても密度が低ければ、推薦は不安定になります。
密度が高くても距離が遠ければ、プロンプトに適合しません。
距離(適合性) × 密度(確信度)
この掛け合わせがLLMOにおける推薦の「確率優位」を生み出します。
確率優位が形成されると、そのブランドは特定条件において“選ばれやすい存在”になります。
この状態が続くと、LLMのなかで
・想起が安定する
・代表例として固定される
・条件反射的に呼び出される
といった現象が起こるようになります。
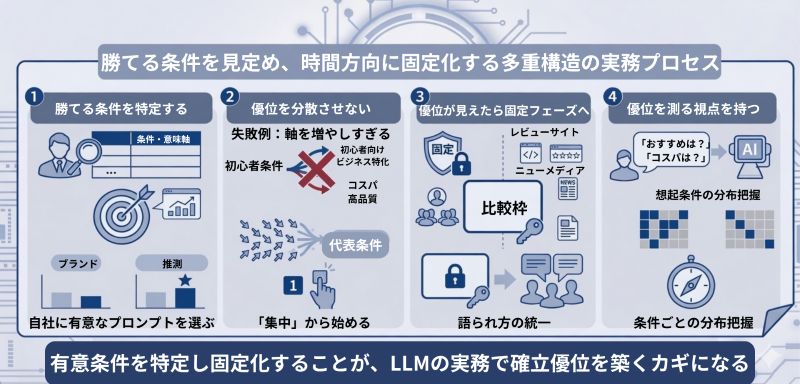
LLMO実務でのポイント ― 確率優位は「選択と集中」で設計する
確率優位の実務は、どの条件で勝つかを決め、
その優位を分散させず、
時間方向に固定することです。
実務では、次の順序で確率優位を設計していきましょう。
① まず「勝てる条件」を特定する
すべての条件で選ばれるブランドは存在しません。
重要なのは、どの条件(=プロンプトが置く意味軸)において競合より優位に立てるのかを見極めることです。
そのためには、以下を明確にしましょう。
・どのプロンプトで想起されたいのか
・どの条件なら競合より距離が近いのか
・どの軸なら意味密度を集中できるのか
ここで重要なのは、絶対評価ではなく相対評価で考えることです。
確率優位は「一番強いブランド」が勝つわけではありません。
その条件において「最も自然に説明できる存在」が選ばれます。
強い軸で戦うのではなく、勝てる軸を選ぶことが確率設計の出発点になります。
たとえば「オンライン英会話」全体で勝とうとするのではなく、
・初心者特化
・短期集中
・法人研修
・価格重視
といった条件単位で優位可能性を見ていきます。
② 優位を分散させない
実務で最も多い失敗は、軸を増やしすぎることです。
初心者向け、ビジネス特化、コスパ、高品質と広げると、密度が分散し、優位は固定されません。
まずは「代表条件」を一つ決めて、その条件で想起が安定してから、次の軸に広げていきましょう。
確率優位は「拡張」ではなく「集中」から始まります。
③ 優位が見えたら固定フェーズに入る
条件単位で想起が発生し始めたら、次は固定フェーズです。
やるべきことは:
・比較枠を固定する
・第三者文脈をその条件に集中させる
・語られ方をぶらさない
ここで失敗すると、確率優位が崩れてしまいます。
確率優位は自然に広がるものではなく、意図的に固定しなければ他の候補に置き換わって可能性があることを、忘れないようにしましょう。
④ 優位を測る視点を持つ
確率優位を設計するためには、実際に生成AIにプロンプトを投げて、自社がどの条件で想起されるかを確認することが重要です。
たとえば、次のようなプロンプトを実際にAIに投げてみましょう。
・「初心者におすすめのオンライン英会話は?」
・「コスパのいいオンライン英会話は?」
・「法人研修に強いオンライン英会話は?」
そのうえで、次の点を確認します。
・その条件で自社は回答に登場するか
・同じ条件で競合はどのように登場するか
・回答の中で自社はどのような特徴として説明されているか
ここで重要なのは、「出たかどうか」だけを見ることではありません。
どの条件では想起され、どの条件では想起されないのか、その分布を把握することです。
この分布を見ることで、自社が優位を持てる条件と、競合が強い条件が見えてきます。
この優位条件を特定することが、確率優位を設計するための鍵になります。
まとめ:LLMからの推薦はどのように形成されるか
生成AIの推薦は、あらかじめ決まった順位ではなく、確率によって選ばれます。
その確率を決めるのが「距離」と「密度」です。
距離とは、ユーザーのプロンプトが求める意味とブランドの意味位置の近さであり、これは主に認識構造によって決まります。
一方、密度とは、その意味方向にどれだけ一貫して意味が蓄積されているかであり、これは主に文脈構造によって形成されます。
距離が近く、かつ密度が高いとき、そのブランドは特定の条件において選ばれやすい状態(確率優位)になります。
実務では、すべての条件で選ばれようとするのではなく、
どの条件で勝つかを決め、意味を集中させ、その優位を固定することが重要です。
生成AI時代の競争は、順位争いではなく、どの条件で選ばれる存在になるかという「確率設計」の競争なのです。
- ✔︎自社・競合をスコアリング
- ✔︎効果の高い引用元がわかる
- ✔︎LLMO虎の巻と連動した施策チェックリスト